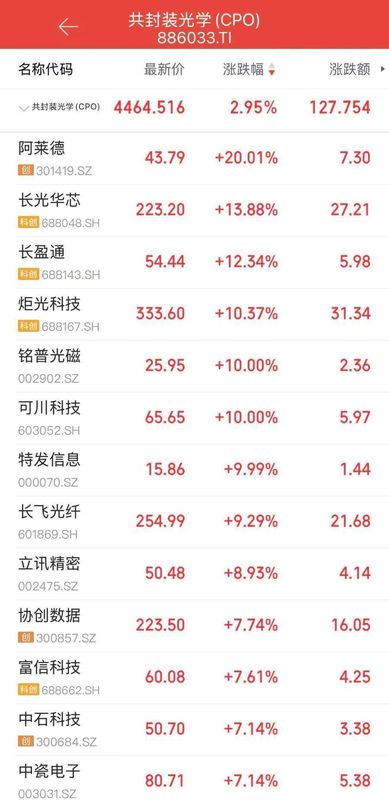
日均调用量突破140万亿,词元(Token)背后的智能蝶变:你是否感知到这场算力革命的脉动?
回望人工智能发展的漫长征途,我们常被那些宏大的算法模型所震撼,却往往忽略了支撑这一切的微小基石——词元(Token)。正如当年互联网普及之初,人们还在争论信息的最小单位一样,今天,当国家数据局明确“词元”这一中文译名时,我们仿佛站在了历史的转折点上。这不仅是一个命名,更是一种对数字基础设施的重新定义与认同。
时间倒回至2024年初,那时我国日均词元调用量尚处于千亿量级。短短两年间,这一数字跃升至140万亿,增长千倍有余。这一数据曲线的陡峭程度,不仅反映了算力需求的指数级爆发,更折射出中国人工智能产业从“实验场”走向“生产线”的深刻转型。在这个过程中,我们见证了从单纯的对话交互,向能够自主决策、执行复杂任务的智能体(Agent)跨越。这种跨越,是技术从量变积累到质变爆发的必然结果,也是每一位从业者在无数次迭代中换来的勋章。
对于身处AI浪潮中的个体而言,理解“词元”的爆发意义重大。它意味着数据不再是沉睡的档案,而是流动的血液,直接驱动着产业的每一次呼吸。在这一背景下,高质量数据集的建设显得尤为关键。从国家层面的规划来看,890PB的高质量数据积累,相当于国家图书馆数字资源总量的310倍。这不仅是数据的堆砌,更是对AI“认知体系”的重塑。对于企业与开发者而言,未来的核心竞争力,正取决于能否在这一庞大的算力底座上,挖掘出最具场景落地价值的“决策模型”。
深度重塑:词元驱动下的决策模型进化论
词元的价值已不再局限于信息传输,它正演变为智能决策的核心载体。随着调用量的激增,模型对于复杂语境的理解与执行能力达到了新的高度。开发者应重点关注如何通过优化数据结构,提升词元处理的精准度,从而实现从“通用智能”向“垂直行业专家智能”的平滑过渡。
在应用层面,智能体的发展路径将更加侧重于“自主性”。未来的AI不仅能“听懂”需求,更应具备在模糊约束下通过多步推理达成目标的能力。这意味着数据准备工作必须前置,将传统的结构化数据转化为更符合神经网络逻辑的语义向量,以应对日益复杂的应用场景需求。
高质量数据集的建设不仅是规模的竞争,更是“AI就绪度”的角逐。企业应当建立起一套动态评估体系,确保在数据清洗、标注及清洗环节中,始终保持对业务逻辑的高度敏感,从而让每一个词元都能成为提升系统效能的有效增量,而非冗余噪声。